


Google presenta TurboQuant para comprimir la memoria de la IA hasta 6 veces sin penalizar el rendimiento
por Edgar OteroGoogle Research ha presentado TurboQuant, una familia de algoritmos de compresión pensada para uno de los cuellos de botella más serios de la inteligencia artificial actual. Nos referimos al consumo de memoria cuando los modelos manejan grandes volúmenes de contexto y operaciones de búsqueda sobre vectores. La compañía sostiene que esta técnica permite reducir de forma drástica el tamaño de la memoria usada por los modelos sin perder precisión, un avance con impacto directo en coste, velocidad y escalabilidad.
La propuesta se apoya en tres piezas. Tenemos TurboQuant como método principal, junto a QJL y PolarQuant como técnicas complementarias. Sobre el papel, el resultado es especialmente relevante para la llamada KV cache, la memoria rápida donde un modelo guarda información intermedia para no recalcularla constantemente mientras genera texto. Cuanto más largo es el contexto y más complejo el uso, mayor es esa carga de memoria, y ahí es donde este anuncio resulta importante para la industria.
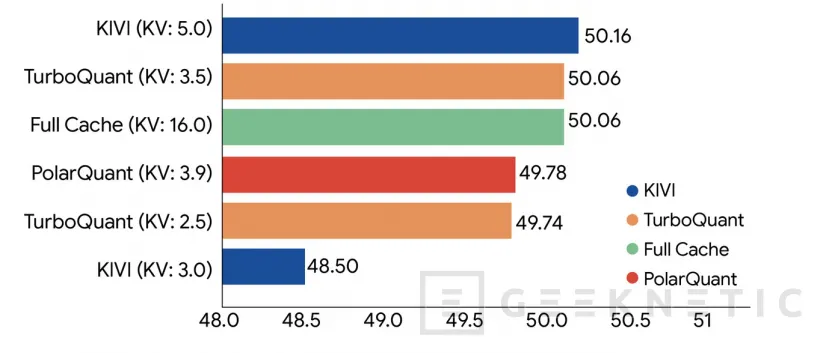
Google asegura que su sistema logra comprimir la KV cache hasta operar con 3 bits en algunos escenarios, frente a formatos mucho más pesados, manteniendo el rendimiento del modelo en pruebas con Gemma, Mistral y Llama. También afirma mejoras de velocidad notables en el cálculo de atención, con cifras de hasta 8 veces más rendimiento frente a claves sin cuantizar en aceleradores H100. Aunque habrá que ver su adopción real fuera de los papers, el mensaje es claro: la eficiencia ya no es un ajuste secundario, sino una condición para que la IA siga creciendo.
Menos memoria, menos coste y más margen para escalar modelos como Gemini
El punto clave aquí es que los modelos actuales no solo dependen de más parámetros, sino de una infraestructura capaz de mover y almacenar enormes cantidades de datos durante la inferencia. Eso encarece el servicio, limita el tamaño del contexto y complica desplegar experiencias más ambiciosas para una cantidad mayor de usuarios. Lo que propone Google puede traducirse en más sesiones simultáneas, menor gasto en hardware y respuestas más rápidas.
La conexión con Gemini es bastante directa. Google lleva tiempo empujando una estrategia en la que sus modelos deben ser no solo capaces, sino también viables a escala comercial y cotidiana. Ya se veía en la apuesta por Gemini 3.1 Flash-Lite para rebajar coste y latencia en la IA de uso diario. TurboQuant encaja como una pieza de infraestructura para sostener esa misma dirección desde abajo: menos memoria por consulta y más eficiencia por cada token procesado.
Además, la presión no viene solo del chatbot clásico. A medida que los asistentes pasan de responder a ejecutar acciones, la demanda de contexto persistente y de consultas rápidas a información relevante aumenta. Esa transición ya se percibe en funciones donde Gemini empieza a usar apps por el usuario en el móvil, una evolución que obliga a servir modelos ágiles, con memoria eficiente y capacidad de operar en tiempo real sin disparar los costes de inferencia.
Por eso este movimiento también debe leerse en clave competitiva. La industria de la IA lleva meses buscando hacer más con menos hardware, ya sea mediante cuantización de pesos, optimización de inferencia, modelos más pequeños o arquitecturas híbridas. Lo que plantea Google aquí es actuar sobre otra capa crítica: la memoria temporal y la representación vectorial, dos elementos que condicionan tanto el rendimiento de los LLM como la viabilidad de los sistemas de búsqueda semántica.
Qué cambia en búsqueda vectorial y por qué este tipo de avances importa más ahora
TurboQuant no se limita a los modelos generativos. Google también lo presenta como una herramienta útil para búsqueda vectorial, un terreno clave en buscadores, recomendación, recuperación semántica y sistemas RAG. En lugar de comparar palabras exactas, estos motores trabajan con vectores que representan significado, intención o similitud. El problema es que esas representaciones ocupan mucho espacio y multiplican el coste cuando la base de datos contiene millones o miles de millones de entradas.
Según los resultados compartidos por la compañía, la técnica mejora la relación entre compresión y precisión frente a métodos previos, con menos sobrecarga de memoria y sin depender tanto de ajustes específicos para cada conjunto de datos. Ese detalle es importante porque, si se confirma en despliegues reales, facilitaría construir índices vectoriales más grandes y más baratos, con tiempos de preparación más bajos y una pérdida mínima en recuperación de resultados relevantes.
Desde un punto de vista técnico, la novedad está en cómo combina varias ideas para reducir el error sin arrastrar el sobrecoste habitual de la cuantización clásica. PolarQuant reorganiza la información de los vectores para representarla de forma más compacta, mientras QJL usa una proyección extremadamente ligera para corregir parte del error residual con apenas un bit adicional. El valor industrial no está tanto en el detalle matemático como en la consecuencia práctica: más eficiencia sin necesidad de reentrenar o afinar modelos para cada caso.
Google presentará TurboQuant en ICLR 2026, mientras que QJL y PolarQuant llegarán a AISTATS 2026. Falta comprobar hasta qué punto estas ideas saltan del entorno de investigación a productos concretos, pero la dirección parece inequívoca.
Fin del Artículo. ¡Cuéntanos algo en los Comentarios!







